♠️University of Waterloo, ♡Votee AI, †Vector Institute [email protected], [email protected], [email protected]
Your browser does not support the video tag.
Trailer video for TheoremExplainAgent **Please turn on the audio for the best experience.**
Abstract
Understanding domain-specific theorems often requires more than just text-based reasoning; effective communication through structured visual explanations is crucial for deeper comprehension. While large language models (LLMs) demonstrate strong performance in text-based theorem reasoning, their ability to generate coherent and pedagogically meaningful visual explanations remains an open challenge. In this work, we introduce TheoremExplainAgent, an agentic approach for generating long-form theorem explanation videos (over 5 minutes) using Manim animations. To systematically evaluate multimodal theorem explanations, we propose TheoremExplainBench, a benchmark covering 240 theorems across multiple STEM disciplines, along with 5 automated evaluation metrics. Our results reveal that agentic planning is essential for generating detailed long-form videos, and the o3-mini agent achieves a success rate of 93.8% and an overall score of 0.77. However, our quantitative and qualitative studies show that most of the videos produced exhibit minor issues with visual element layout. Furthermore, multimodal explanations expose deeper reasoning flaws that text-based explanations fail to reveal, highlighting the importance of multimodal explanations.
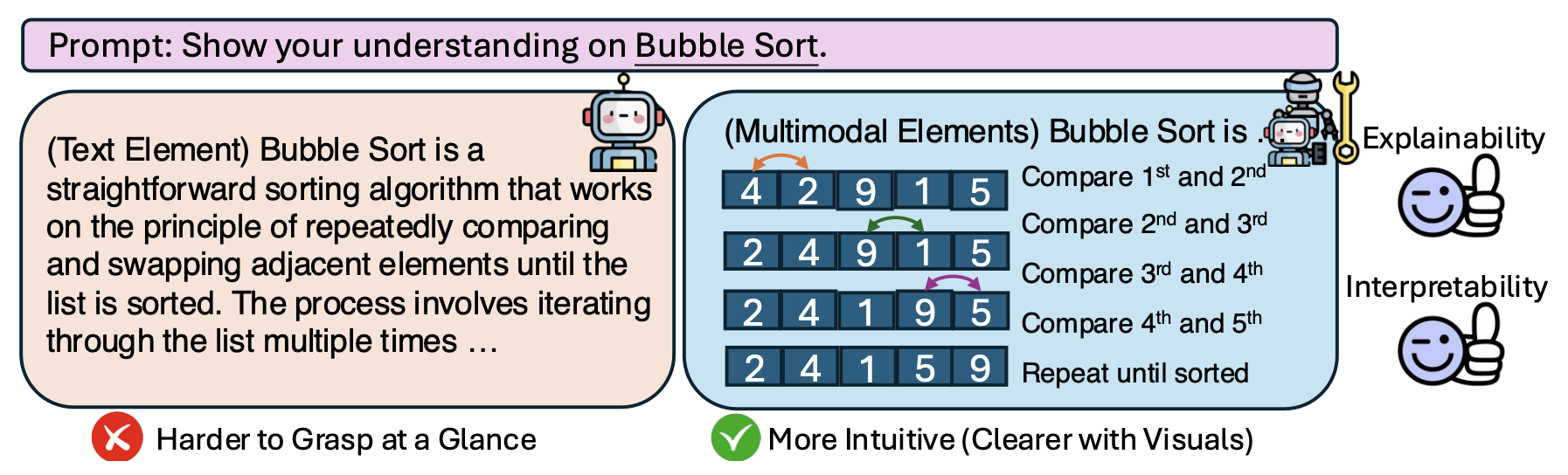
Figure 1: We do not have knowledge of a thing until we have grasped its cause (Aristotle, 1901). A strong reasoning model should not only generate correct conclusions but also communicate them effectively. Visualization enhances human intuition by making abstract concepts more concrete and revealing hidden relationships. Moreover, visual explanations expose reasoning errors more clearly than text, making it easier to diagnose model mistakes.
How TheoremExplainAgent works?
We introduce TheoremExplainAgent (TEA): a novel agentic system designed to generate explanatory videos of mathematical and scientific theorems. TEA employs a two-agent architecture: a planner agent that creates coherent story plans and narrations, and a coding agent that generates Python animation scripts with Manim. This allows the system to produce long, coherent, and pedagogically meaningful videos capable of effectively communicating complex concepts across various STEM disciplines, exposing deeper reasoning flaws that text-based evaluations often miss. To evaluate the efficacy of AI-generated explanations, and specifically those produced by TEA, we introduce TheoremExplainBench (TEB): a benchmark suite comprising 240 meticulously selected theorems. TEB assesses explanations on five key dimensions: accuracy, depth, logical flow, visual relevance, and element layout, ensuring a comprehensive evaluation of pedagogical soundness. We believe TEA, coupled with the rigorous evaluation provided by TEB, will drive advancements in AI systems capable of generating truly insightful and educational explanations.
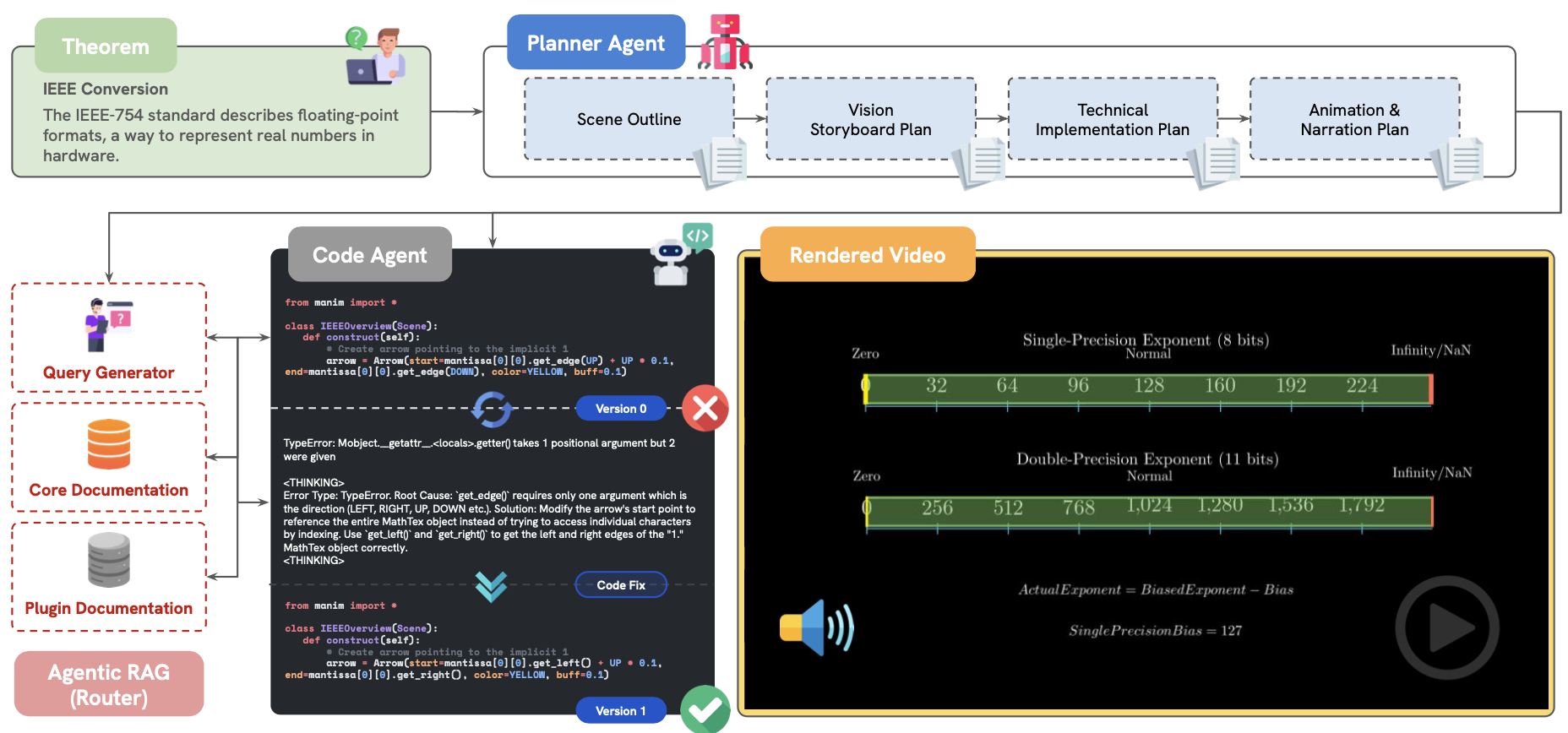
Figure 2: TheoremExplainAgent consists of two LLM agents. Taking a theorem as input, the planner agent create plans for execution. The coding agent then generates Python scripts to produce visuals and audio.
Experimental Results
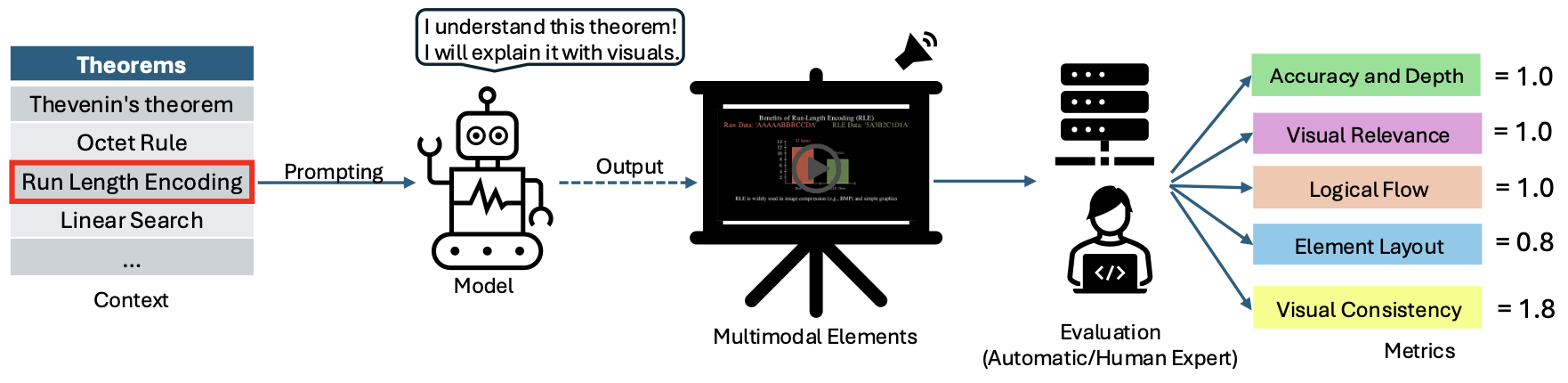
Figure 3: An overview of the multimodal theorem explanation framework.
Based on our proposed benchmark evaluation metrics, we conducted evaluations on different large language models (LLMs) to assess their respective capabilities. The evaluations were performed using both pure inferencing and retrieval-augmented generation (RAG) methods. Below are the detailed results from our experiments:
| Agent | Easy | Medium | Hard | Math | Phys | CS | Chem | Overall |
|---|---|---|---|---|---|---|---|---|
| GPT-4o | 61.3% | 57.5% | 46.2% | 61.7% | 55.0% | 58.3% | 45.0% | 55.0% |
| GPT-4o + RAG | 42.5% | 57.5% | 37.5% | 70.0% | 40.0% | 41.7% | 31.7% | 45.8% |
| Claude 3.5-Sonnet v1 | 2.5% | 1.2% | 2.5% | 1.7% | 1.7% | 1.7% | 3.3% | 2.1% |
| Claude 3.5-Sonnet v1 + RAG | 18.8% | 13.8% | 11.2% | 23.3% | 10.0% | 20.0% | 5.0% | 14.6% |
| Gemini 2.0-Flash | 20.0% | 11.2% | 12.5% | 16.7% | 8.3% | 21.7% | 11.7% | 14.6% |
| Gemini 2.0-Flash + RAG | 23.8% | 21.2% | 16.2% | 26.7% | 15.0% | 20.0% | 20.0% | 20.4% |
| o3-mini (medium) | 93.8% | 91.2% | 96.2% | 95.0% | 93.3% | 93.3% | 93.3% | 93.8% |
| o3-mini (medium) + RAG | 83.8% | 82.5% | 80.0% | 81.7% | 90.0% | 88.3% | 68.3% | 82.1% |
Table 1: Agent Success Rate in Generating Complete Videos
| Agent | Accuracy and Depth | Visual Relevance | Logical Flow | Element Layout | Visual Consistency | Overall Score |
|---|---|---|---|---|---|---|
| GPT-4o | 0.79 | 0.79 | 0.89 | 0.59 | 0.87 | 0.78 |
| GPT-4o + RAG | 0.75 | 0.77 | 0.88 | 0.57 | 0.86 | 0.76 |
| Claude 3.5-Sonnet v1 | 0.75 | 0.87 | 0.88 | 0.57 | 0.92 | 0.79 |
| Claude 3.5-Sonnet v1 + RAG | 0.67 | 0.79 | 0.69 | 0.65 | 0.87 | 0.71 |
| Gemini 2.0 Flash | 0.82 | 0.77 | 0.80 | 0.57 | 0.88 | 0.76 |
| Gemini 2.0 Flash + RAG | 0.79 | 0.75 | 0.84 | 0.58 | 0.87 | 0.76 |
| o3-mini (medium) | 0.76 | 0.76 | 0.89 | 0.61 | 0.88 | 0.77 |
| o3-mini (medium) + RAG | 0.75 | 0.75 | 0.88 | 0.61 | 0.88 | 0.76 |
| Human-made Manim Videos | 0.80 | 0.81 | 0.70 | 0.73 | 0.87 | 0.77 |
Table 2: Performance of Proposed Metrics on Successfully Generated Videos
Rendered Theorem Explanation Videos Example (Sound On 🔊)
\
High Quality Videos
Physics - Geometric Brownian Motion
Computer Science - Gradient Descent
Math - Properties of Kites
Math - Rational Zero Theorem
Math - Integration By Substitution
Chemistry - Kjeldahl Method
Physics - Geometric Brownian Motion
Computer Science - Gradient Descent
Math - Properties of Kites
Math - Rational Zero Theorem
Math - Integration By Substitution
Chemistry - Kjeldahl Method
Physics - Geometric Brownian Motion
Computer Science - Gradient Descent
Math - Properties of Kites
Math - Rational Zero Theorem
Math - Integration By Substitution
Chemistry - Kjeldahl Method
Physics - Geometric Brownian Motion
\
Poor Quality Videos
Physics - Electromagnetic Spectrum
Computer Science - K Means Clustering
Physics - Virial Theorem
Chemistry - Hard Acid Soft Base Theory
Math - Pythagorean Theorem
Chemistry - Michaelis Menten Kinetics
Physics - Electromagnetic Spectrum
Computer Science - K Means Clustering
Physics - Virial Theorem
Chemistry - Hard Acid Soft Base Theory
Math - Pythagorean Theorem
Chemistry - Michaelis Menten Kinetics
Physics - Electromagnetic Spectrum
Computer Science - K Means Clustering
Physics - Virial Theorem
Chemistry - Hard Acid Soft Base Theory
Math - Pythagorean Theorem
Chemistry - Michaelis Menten Kinetics
Physics - Electromagnetic Spectrum
Case Study
A key finding is that visual explanations significantly improve error diagnosis compared to text-based explanations. While text can reveal that an error exists (as seen in Figure 4), it often fails to elucidate why the error occurred. For instance, a text explanation might indicate incorrect application of the chain code theorem without pinpointing the underlying flaw in reasoning. In contrast, video-based explanations readily expose misunderstandings. Incorrect movement direction encodings and misplaced arrows directly reveal misinterpretations of the chain coding process. This demonstrates that visual explanations are not merely confirmations of errors; they are powerful diagnostic tools that uncover the root causes, leading to more effective analysis of AI-generated outputs.
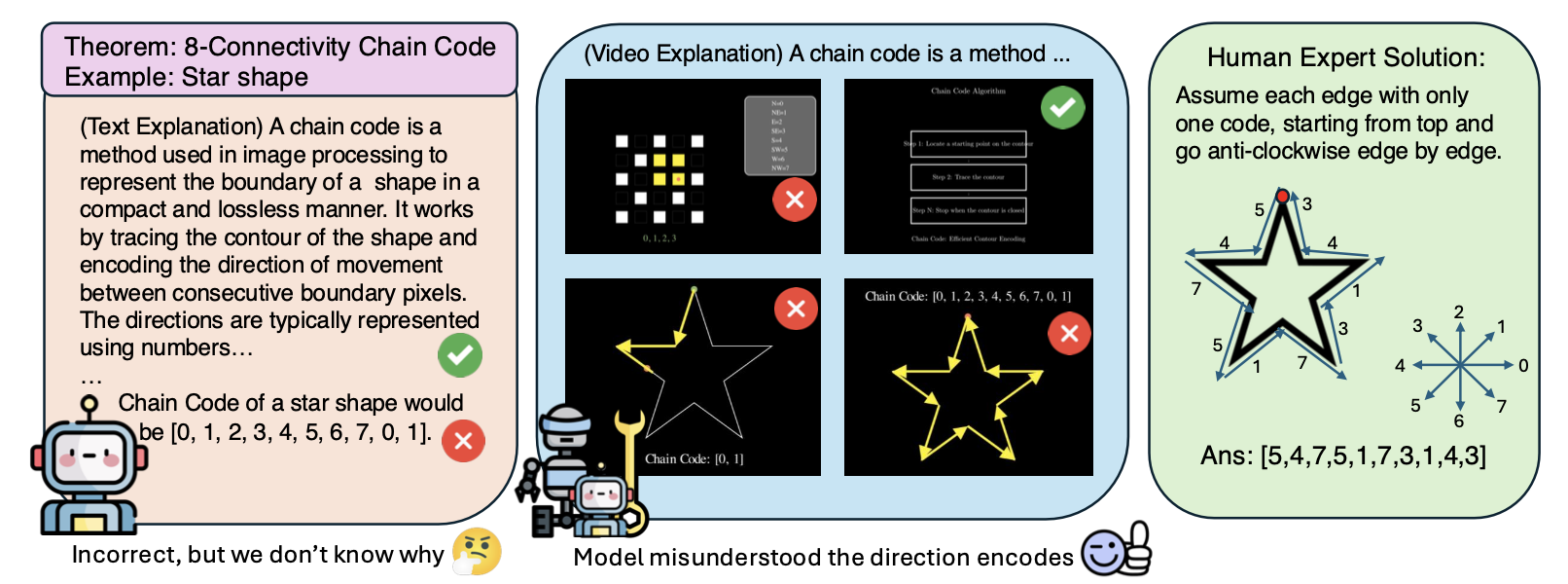
Figure 4: Visualizations expose reasoning errors more clearly than text, facilitating easier diagnosis.
Dataset Details: TheoremExplainBench (TEB)
TheoremExplainBench (TEB) is a curated dataset designed to evaluate the capability of AI systems to generate multimodal explanations of theorems. The dataset comprises 240 theorems sourced from Computer Science, Chemistry, Mathematics, and Physics, providing a diverse assessment of reasoning and visualization skills.
Each theorem includes its name and a contextual description, sourced from OpenStax and LibreTexts. Theorems are categorized into Easy, Medium, and Hard difficulty levels, with 80 entries per category. TEB encompasses 68 distinct subfields, enabling focused analysis of AI performance across specific STEM domains.
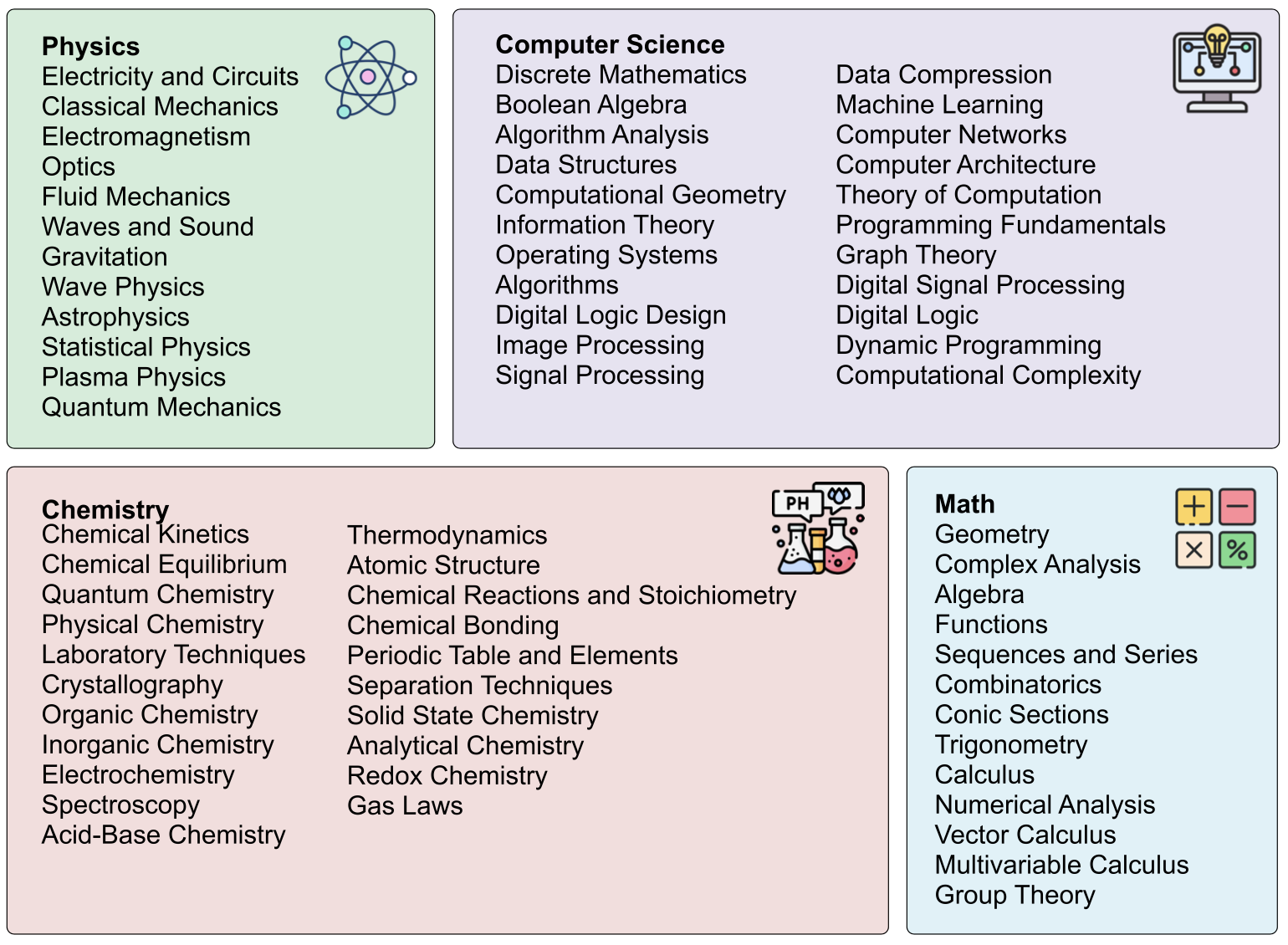
Figure 5: Subfields of TheoremExplainBench under Computer Science, Chemistry, Mathematics, and Physics.
Citation
Please kindly cite our paper if you use our code, data, models or results:
@misc{ku2025theoremexplainagentmultimodalexplanationsllm,
title={TheoremExplainAgent: Towards Multimodal Explanations for LLM Theorem Understanding},
author={Max Ku and Thomas Chong and Jonathan Leung and Krish Shah and Alvin Yu and Wenhu Chen},
year={2025},
eprint={2502.19400},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2502.19400},
}